01 前馈神经网络
基本概念
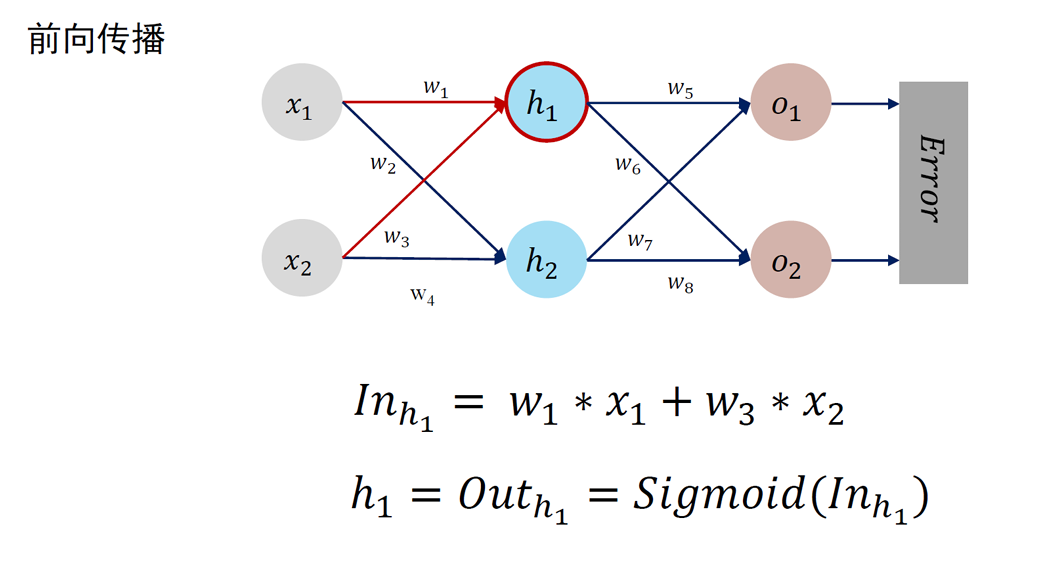
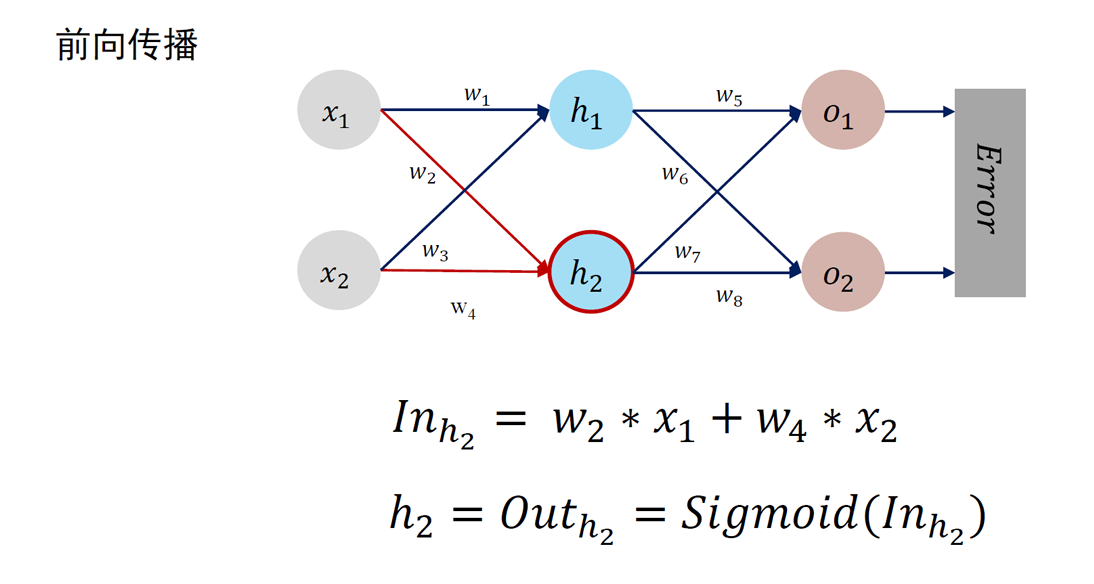
神经元是深度学习模型中基本单位。可以如下刻画神经元功能:
- 对相邻前向神经元输入信息进行加权累加:
- 对累加结果进行非线性变换 (通过激活函数)
- 神经元的输出:Out
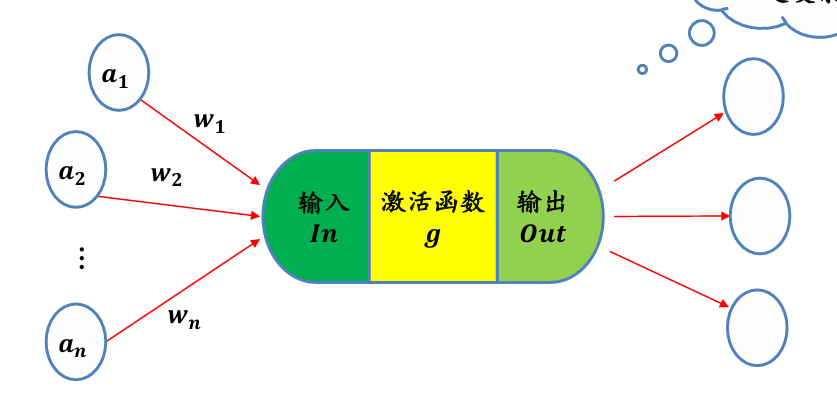
神经网络使用非线性函数作为激活函数(activation function),通过对多个非线性函数进行组合,来实现对输入信息的非线性变换:
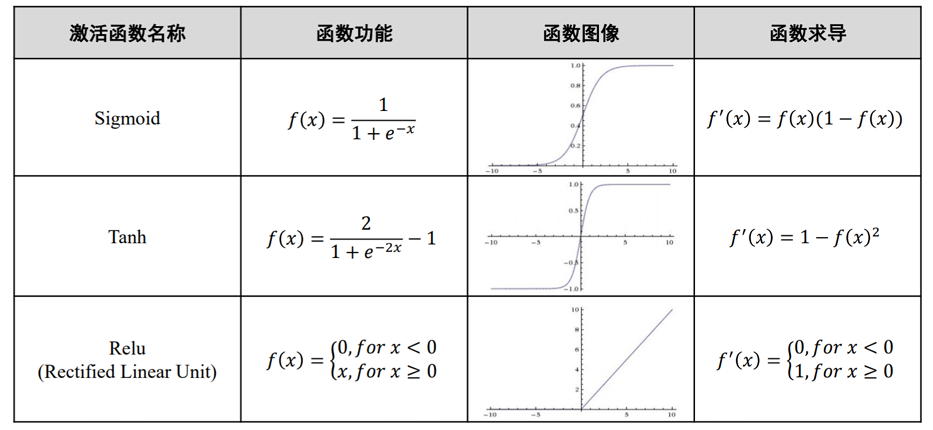
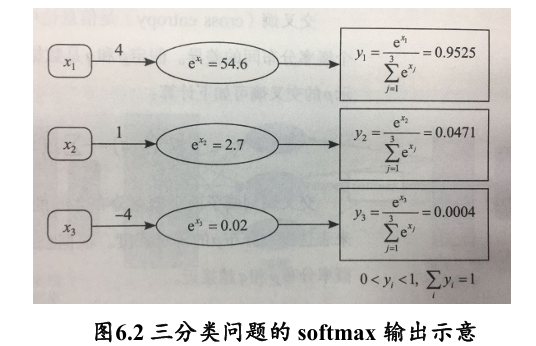
Softmax 函数一般用于多分类问题中,其将输入数据 映射到第 个类别的概率 如下计算:
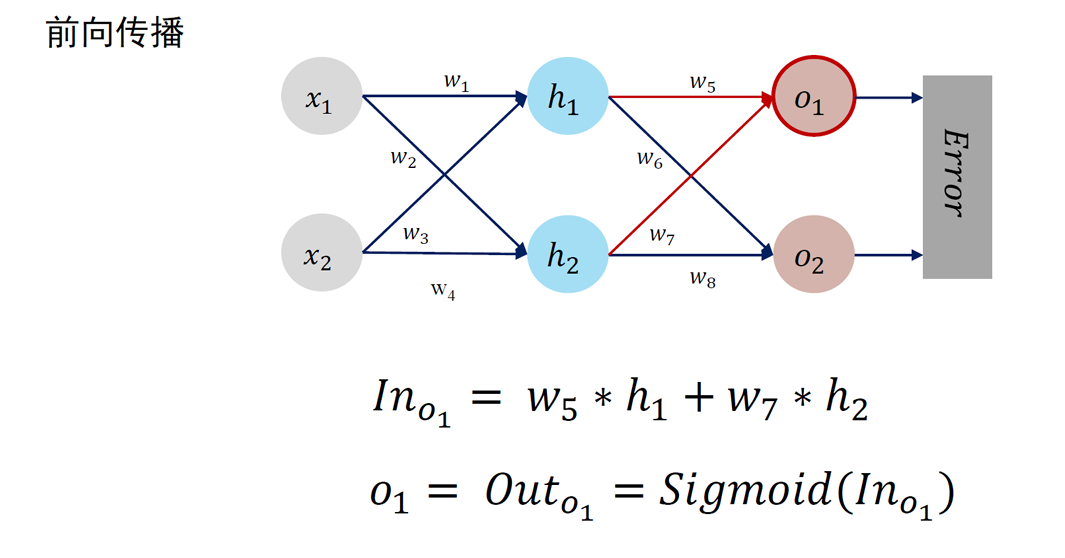
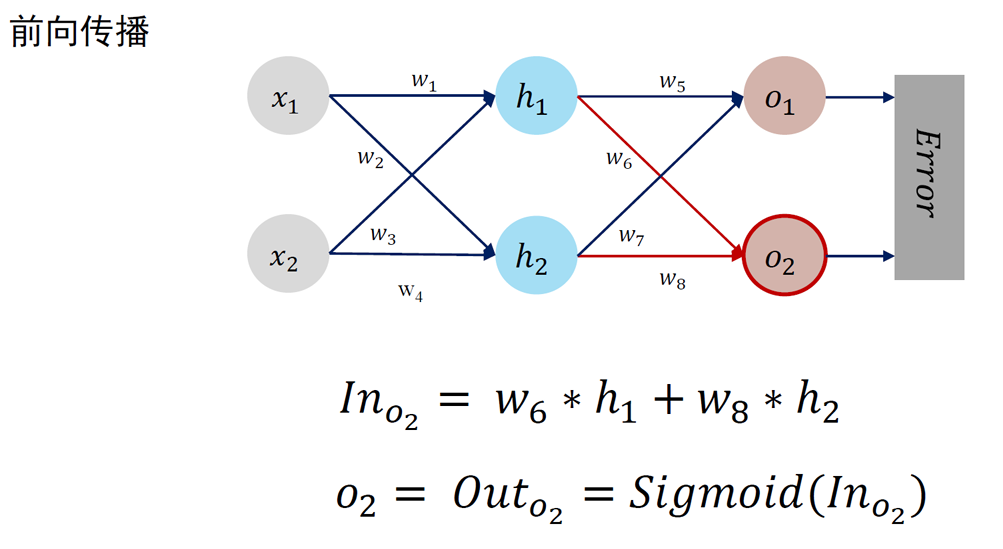
前馈神经网络(feedforward neural network)
- 各个神经元接受前一级的输入,并输出到下一级,模型中没有反馈
- 层与层之间通过“全连接”进行链接,即两个相邻层之间的神经元完全成对连接,但层内的神经元不相互连接
损失函数(Loss Function):计算模型预测值与真实值之间的误差
- 均方误差损失函数:计算预测值和实际值之间距离(即误差)的平方来衡量模型优劣
- 交叉熵损失函数:度量两个概率分布间的差异交叉熵越小,两个概率分布 p 和 q 越接近
Softmax 和交叉熵损失函数相互结合,为偏导计算带来了极大便利 Softmax with cross-entropy loss
感知机模型
早期的感知机结构和 MCP 模型相似,由一个输入层和一个输出层构成,因此也被称为 “单层感知机”。感知机的输入层负责接收实数值的输入向量,输出层则能输出 1 或 -1 两个值
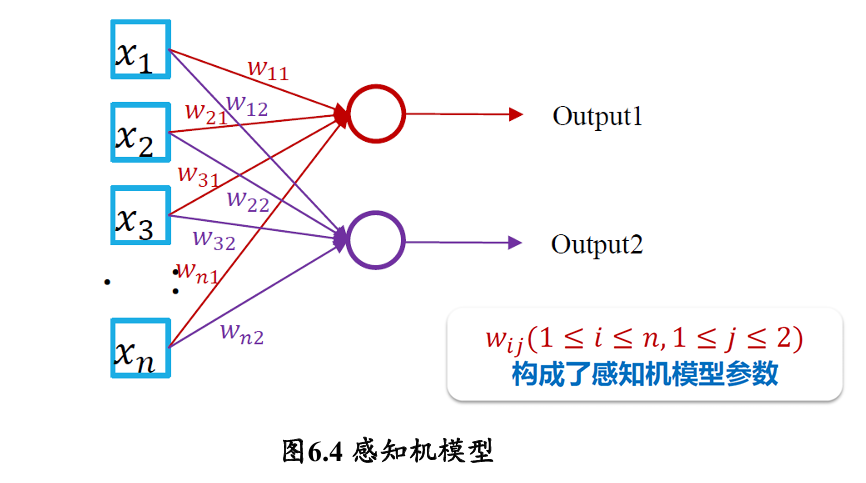
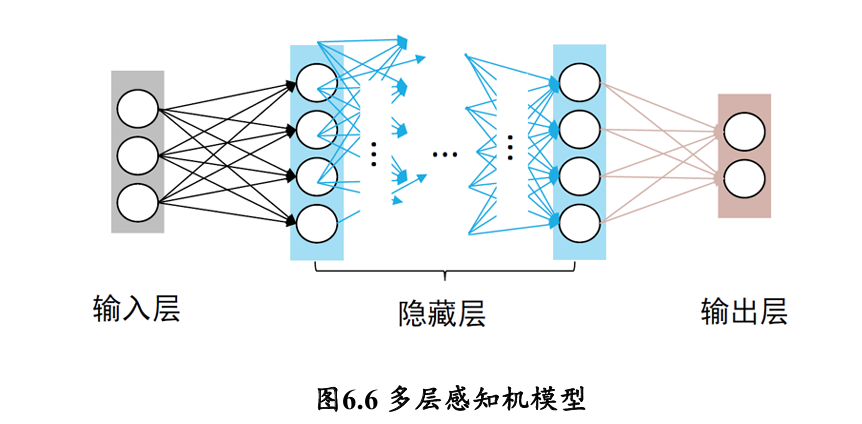
多层感知机由输入层、输出层和至少一层的隐藏层构成
- 网络中各个隐藏层中神经元可接收相邻前序隐藏层中所有神经元传递而来的信息,经过加工处理后将信息输出给相邻后续隐藏层中所有神经元。
- 各个神经元接受前一级的输入,并输出到下一级,模型中没有反馈
- 层与层之间通过“全连接”进行链接,即两个相邻层之间的神经元完全成对连接,但层内的神经元不相互连接
- 也就是前馈神经网络 feedforward neural network
如何优化网络参数?
从标注数据出发,优化模型参数
- 标注数据:
- 评分函数 (scoring function) 将输入数据映射为类别置信度大|小:s
- 损失函数来估量模型预测值与真实值之间的差距。损失函数给出的差距越小,则模型鲁棒性就越好。|常用的损失函数有 softmax 或者 SVM
梯度下降 Gradient Descent
梯度下降算法是一种使得损失函数最小化的方法。一元变量所构成函数𝒇在𝒙处梯度为:
- 在多元函数中,梯度是对每一变量所求导数组成的向量
- 梯度的反方向是函数值下降最快的方向,因此是损失函数求解的方向
假设损失函数 是连续可微的多元变量函数, 其泰勒展开如下 ( 是微小的增量):
- 为了保证 , 我们选择让 与梯度 的方向相反。最简单的选择是让
正比于梯度的负方向:
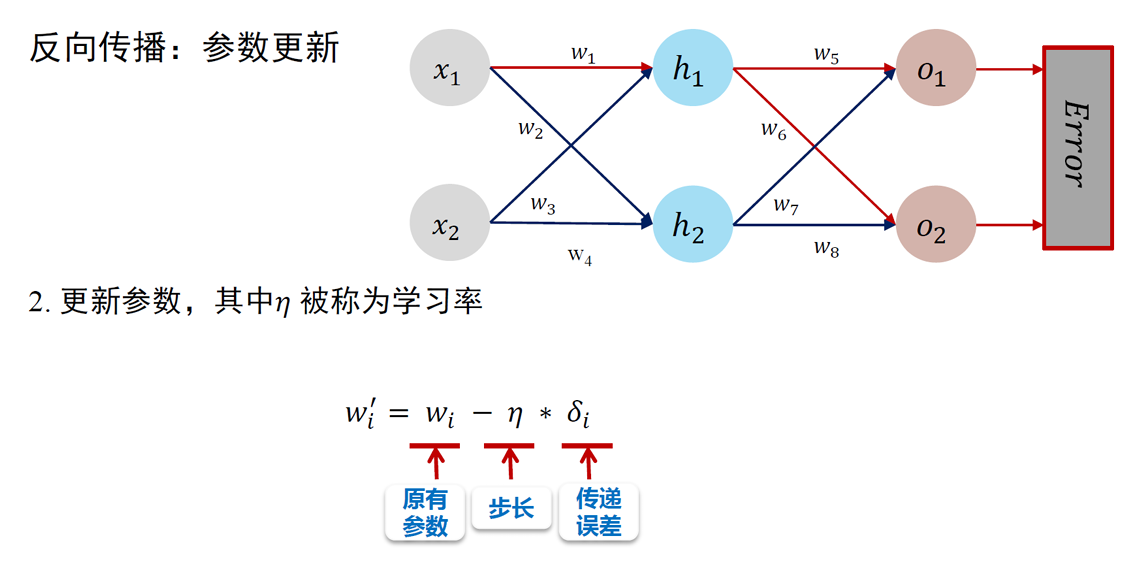
- 其中, 是一个正的常数,称为学习率 (learning rate) 或步长 (step size)。学习率控制着每次迭代中参数更新的幅度。
- 将 代入 , 得到参数的更新公式:
- 这个公式表示在每次迭代中,我们都沿着当前点 处梯度 的反方向移动一小步 (步长为 ), 从而更新参数到 , 希望能够逐步接近损失函数的最小值
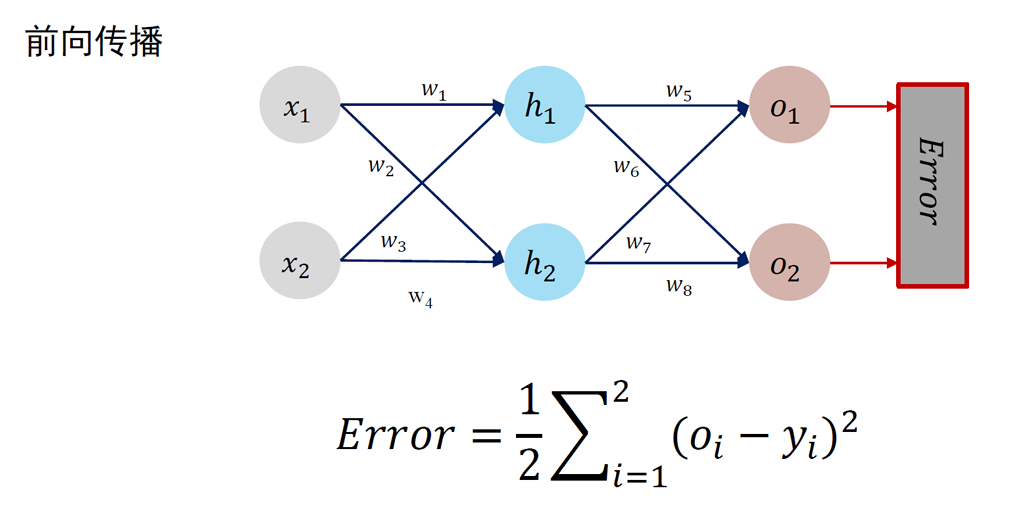
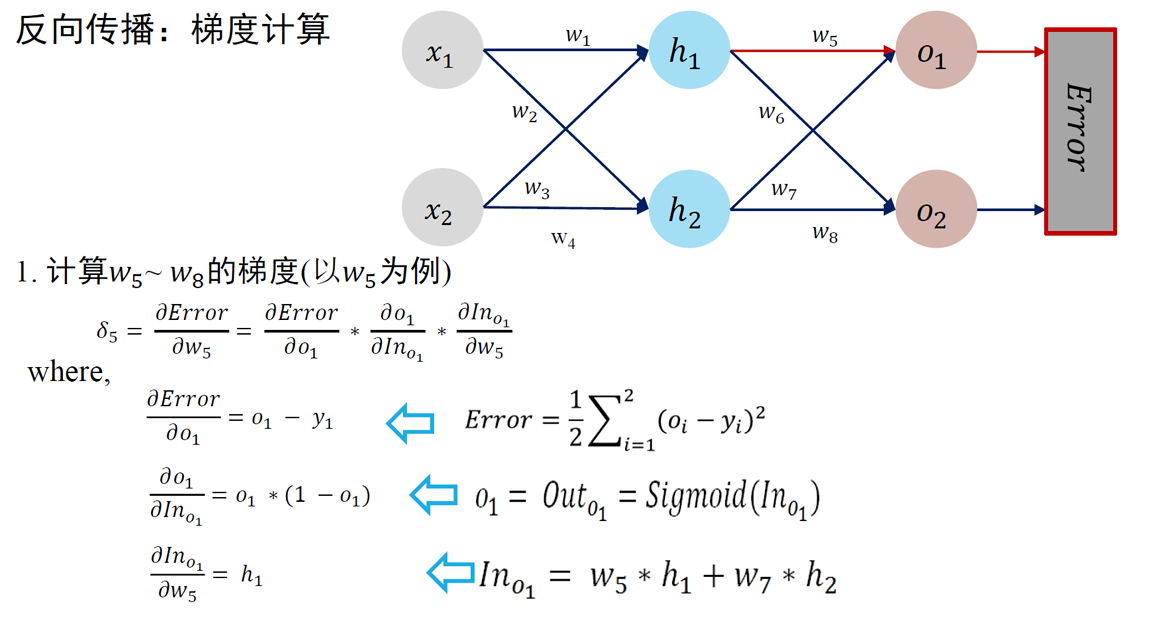
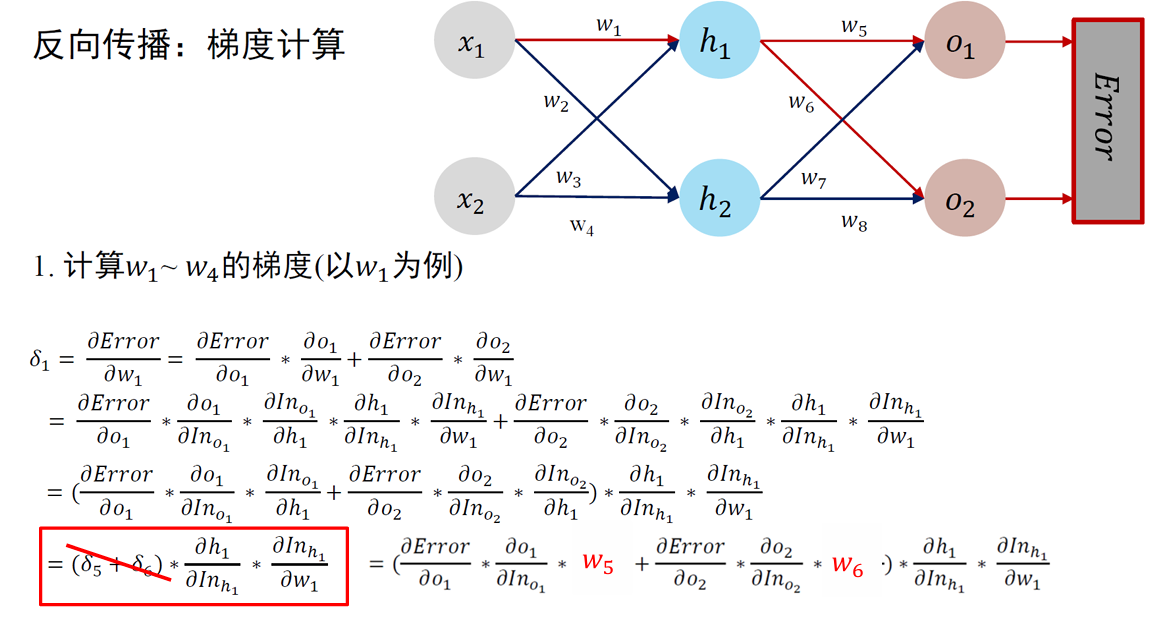
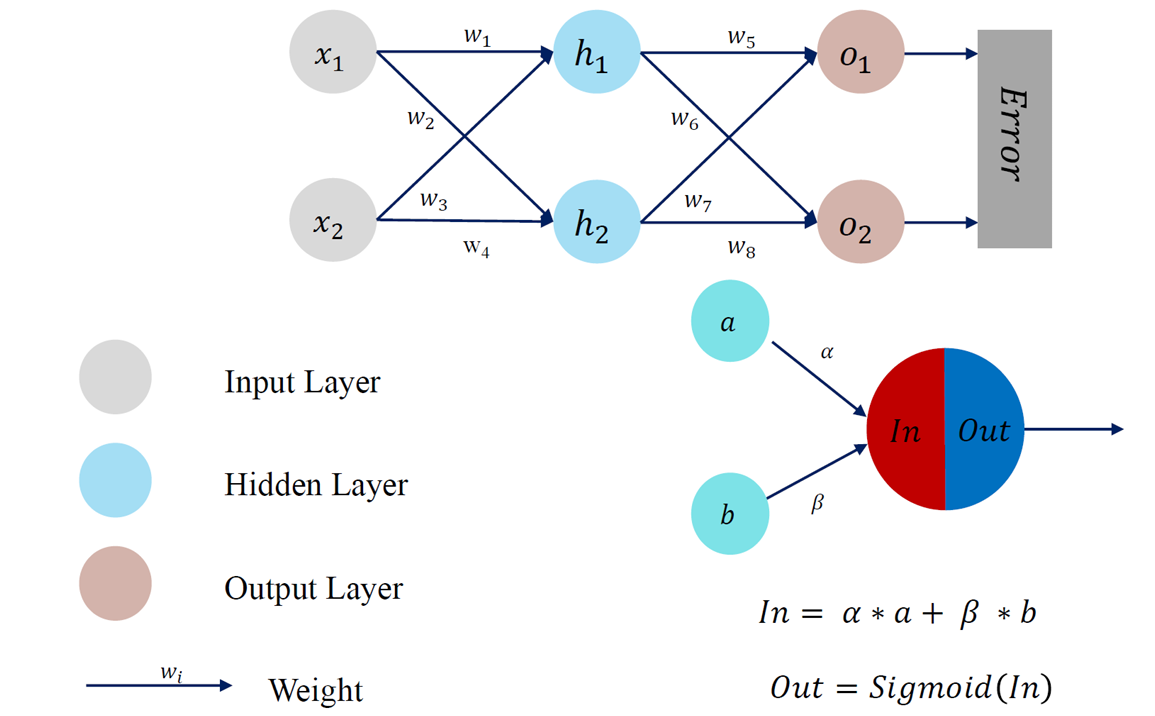
误差反向传播 Error Back Propagation (BP)
BP 算法是一种将输出层误差反向传播给隐藏层进行参数更新的方法
梯度下降算法
- 批量梯度下降(Batch Gradient Descent, BGD)
- 一次迭代对所有样本进行计算,利用矩阵进行操作可实现并行
- 当目标函数为凸函数时,BGD 一定能够得到全局最优
- 当样本数目很大时,每迭代一步都需要对所有样本计算,训练过程会很慢
- 随机梯度下降(Stochastic Gradient Descent,SGD)
- 在每轮迭代中,随机优化一个样本的损失,每一轮参数的更新速度大大加快
- 准确度下降。即使目标函数为强凸函数,SGD 仍无法线性收敛
- 可能会收敛到局部最优,由于单个样本不能代表全体样本趋势
- 不易于实现并行
- 小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
- 每次迭代使用 batch_size 个样本来对参数进行更新
在合理地范围内,增大 batch size 的好处:
- 内存利用率提高了
- 跑完一次 epoch (全数据集) 所需的迭代次数减少
- 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小
盲目增大 batch_size 的坏处:
- 内存容量可能撑不住了
- 跑完一次 epoch (全数据集) 所需的迭代次数减少,但要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢
- Batch Size 增大到一定程度,其确定的下降方向已经基本不再变化
02 卷积神经网络 CNN
为什么需要卷积神经网络👇
当模型参数数量变得巨大时,不仅会占用大量计算机内存,同时也使神经网络模型变得难以训练收敛。因此,对于图像这样的数据,不能直接将所构成的像素点向量与前馈神经网络神经元相连。
2.1 卷积
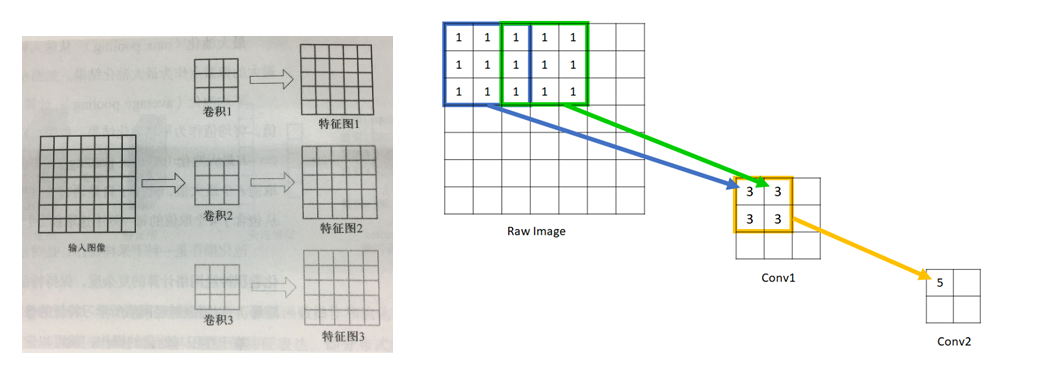
- 卷积(convolution):就是针对像素点的空间依赖性来对图像进行处理的一种技术
- 卷积核(kernel):一个二维矩阵 (可以是多维的,例如 RGB 图像,有三维的卷积核,分别针对三个通道进行 convolution)
- 卷积操作:
- 步长 Stride:每进行一次卷积计算后,卷积核移动的格数
- 感受野(receptive field):感受野是特征图上一个点对应输入图像上的区域
不同卷积核可被用来刻画视觉神经细胞对外界信息感受时的不同选择性:
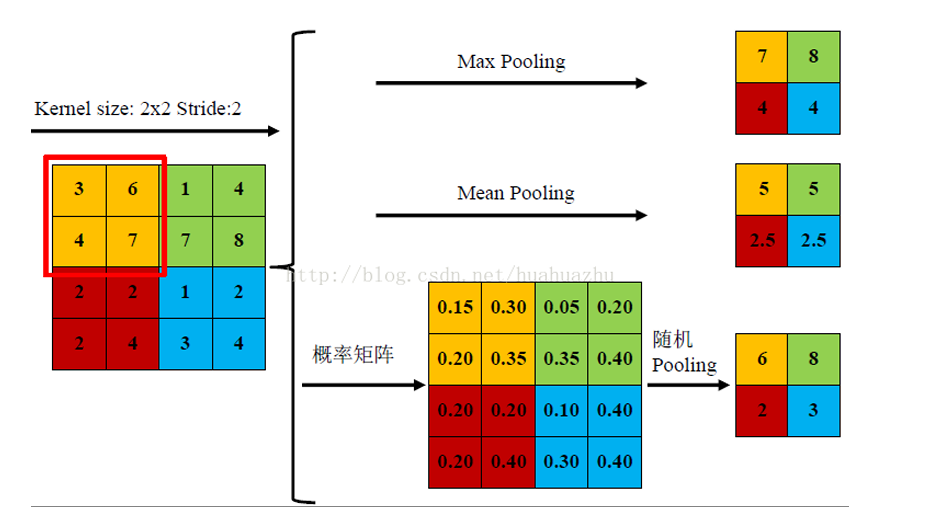
2.2 池化
图像中存在较多冗余,可用某一区域子块的统计信息 (如最大值或均值等)来刻画该区域中所有像素点呈现的空间分布模式
池化 Pooling: 对输入的特征图进行下采样,以获得最主要的信息
- Max Pooling
- Mean Pooling
- Stochastic Pooling (对像素点按照数值大小赋予概率)
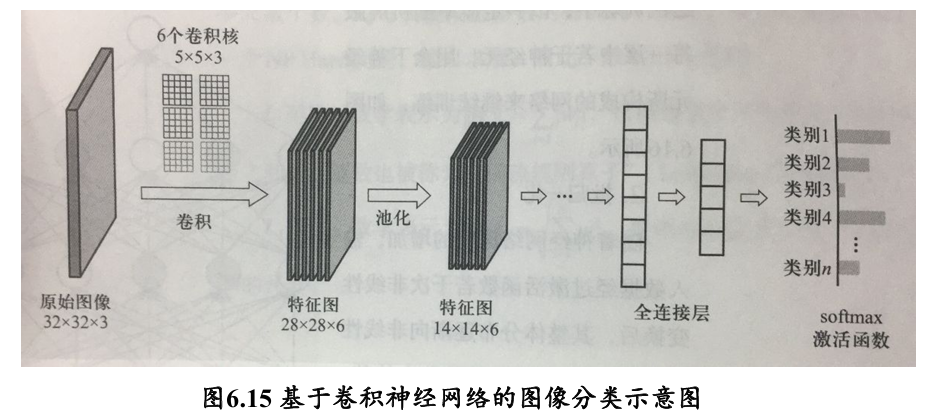
分布式向量表达 (distributed vector representation):卷积神经网络在若干次卷积操作、接着对卷积所得结果进行激活函数操作和池化操作下,最后通过全连接层来学习得到输入数据的特征表达
- 卷积层:提取局部特征
- 池化层:降维
- 激活函数:非线性化
- 全连接层:用于输出想要的结果 (下游任务)
2.3 正则化
正则化系数 👉 缓解神经网络在训练过程中出现的过拟合问题
有如下几种方法:
- Dropout
每次参数更新时随机丢掉一部分神经元来减少神经网络复杂度,防止过拟合
- Batch-Normalization(批归一化)
通过规范化的手段,把神经网络每层中任意神经元的输入值分布改变到均值为 0、方差为 1 的标准正态分布
- L1-Norm & L2-Norm
范数:数学表示为 , 指模型参数 中各个元素的绝对值之和
范数也被称为 “稀疏规则算子” ( Lasso regularization)
范数:数学表示为 , 指模型参数 中各个元素平方和的开方
"结构风险最小化"
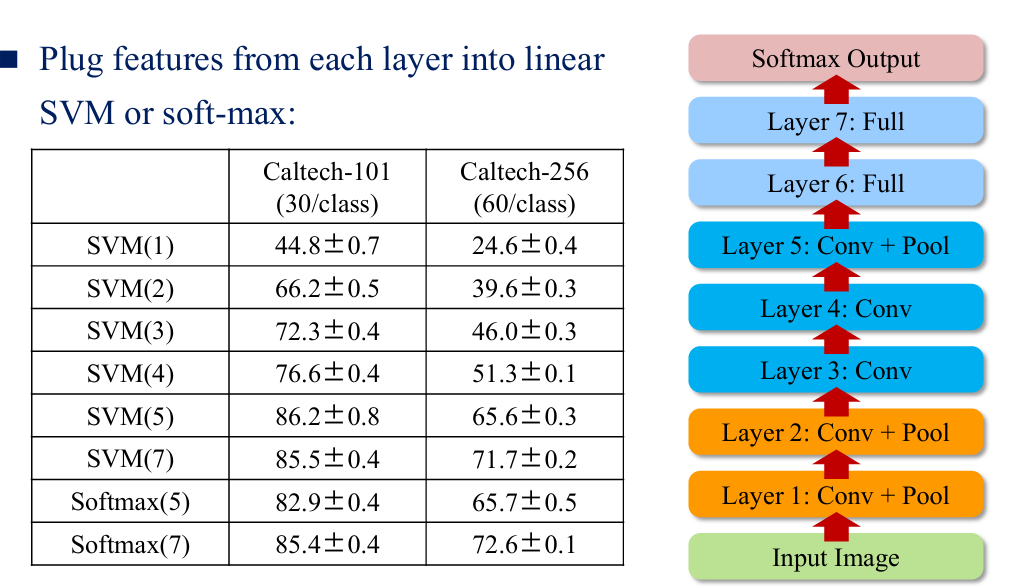
2.4 AlexNet
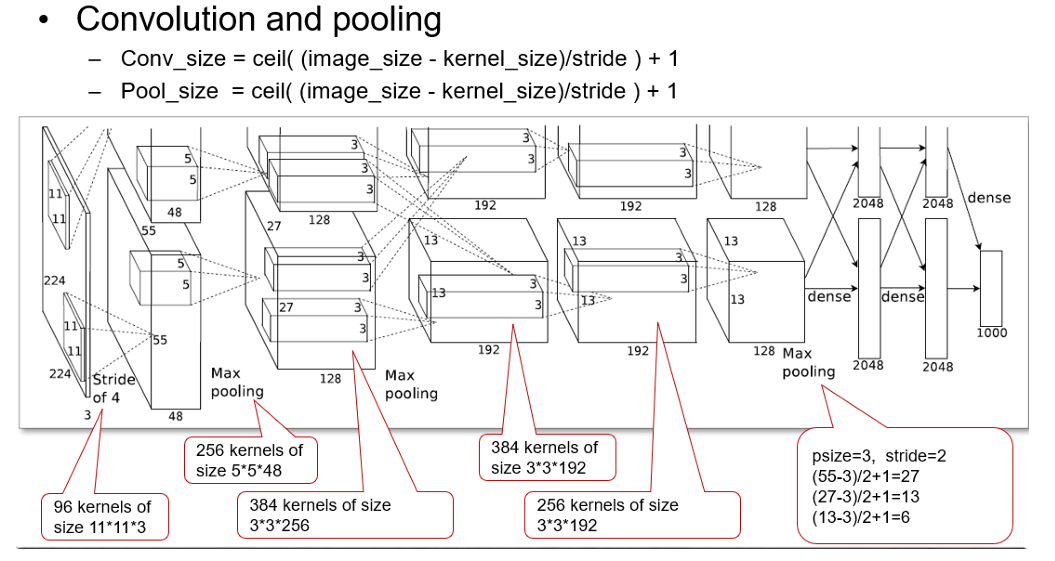
- 当去掉的层数过多时,性能会发生明显的下降
03 循环神经网络 RNN
循环神经网络:一类处理序列数据(如文本句子、视频帧等)时所采用的网络结构
- 本质是希望模拟人所具有的记忆能力,在学习过程中记住部分已经出现的信息,并利用所记住的信息影响后续结点输出
3.1 基本架构
在时刻 , 一旦得到当前输入数据 , 循环神经网络会结合前一时刻 得到的隐式编码 , 如下产生当前时刻隐式编码
$$h_t=\Phi(\mathrm{U}\times x_t+\mathrm{W}\times h_{t-1})$$
- 这里 是激活函数,一般可为 Sigmoid 或者 Tanh 激活函数,使模型能够忘掉无关的信息,同时更新记忆内容。U 与 W 为模型参数
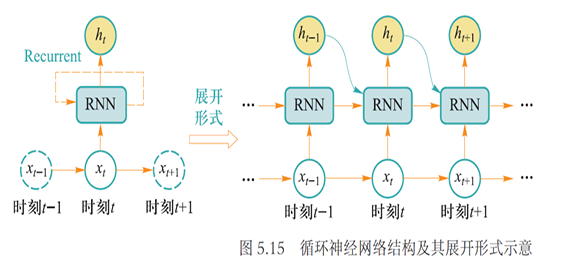
循环神经网络读入每个单词后,先产生对应单词的隐式编码,再如下得到一个句子的向量编码:
- 最后一个单词输出作为整个句子的编码
- 将每个单词的隐式编码进行加权平均,将加权平均结果作为整个句子的向量编码表示
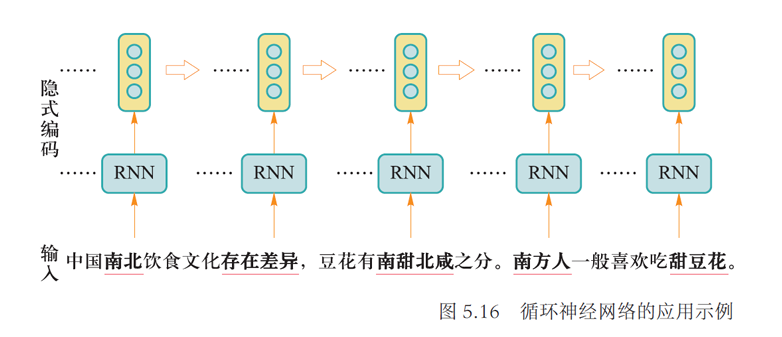
3.2 梯度传递
- 时刻 输入数据 (文本中的单词) 的隐式编码为 、其真实输出为 (单词词性)、模型预测 的词性是
- 参数 将 映射为隐式编码 、参数 将 映射为预测输出 、 通过参数 参与 的生成。
- 图中 、 和 是复用参数
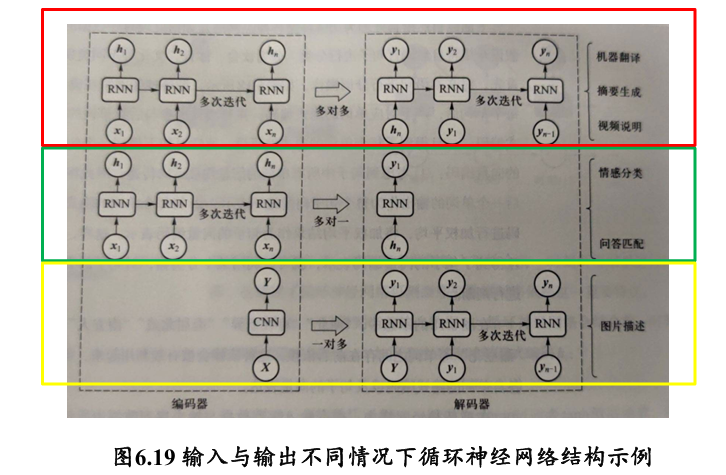
3.3 基本结构
一些基本的 RNN 结构:
- 多对多 👉 机器翻译
- 多对一 👉 情感分类
- 一对多 👉 图像描述生成
双向循环神经网络:
e.g. 我的手机坏了,我打算____一部新手机
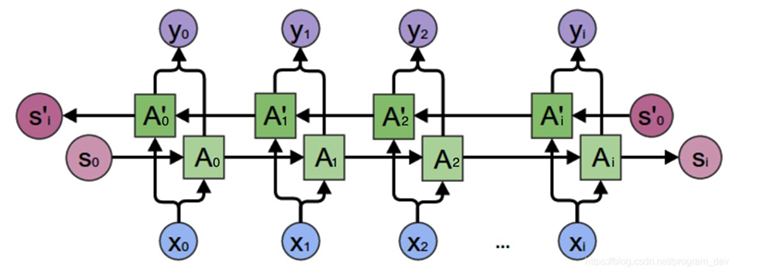
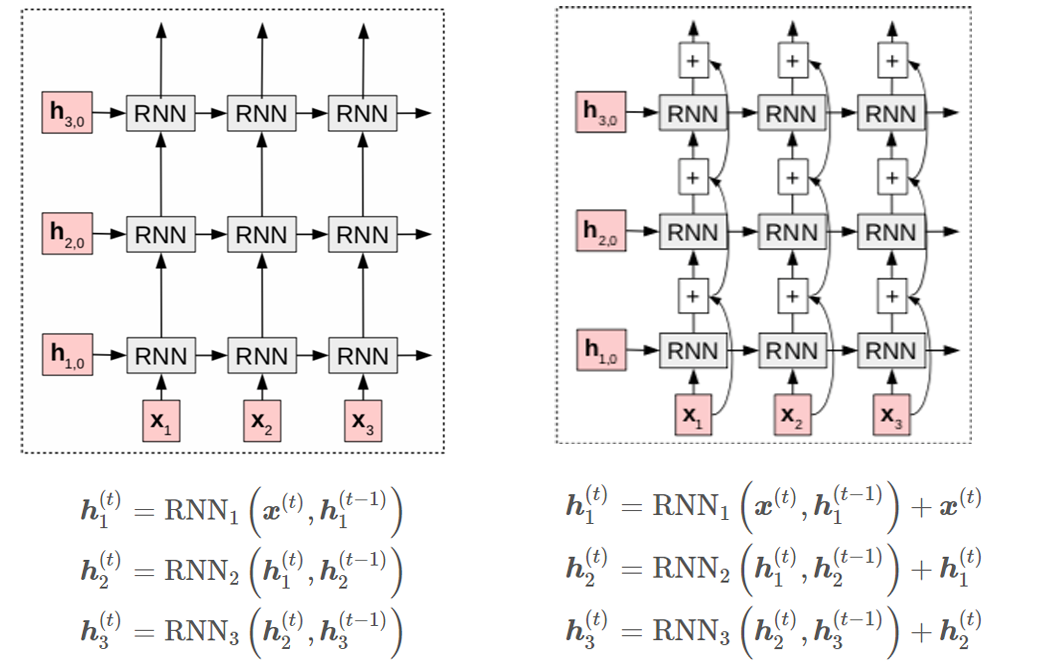
堆叠(多层)循环神经网络:
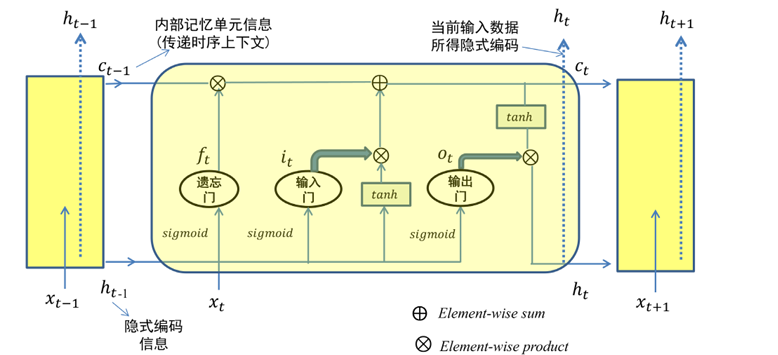
3.4 LSTM
由于 tanh 函数的导数取值位于 0 到 1 区间,对于长序列而言,若干多个 0 到 1 区间的小数相乘,会使得参数求导结果很小,引发梯度消失问题。为了解决梯度消失问题,长短时记忆模型(LongShort-Term Memory,LSTM)被提出
| 符号 |
内容描述/操作 |
|
时刻 t 输入的数据 |
|
输入门的输出:
( 、 和 为输入门的参数)
输入门 控制有多少信息流入当前时刻内部记忆单元 |
|
遗忘门的输出:
( 、 和 为遗忘门的参数)
遗忘门控制上一时刻内部记忆单元 中有多少信息可累积到当前时刻内部记忆单元 |
|
输出门的输出:
( 、 和 为输出门的参数)
输出门控制 最终向 的输出情况 |
|
内部记忆单元的输出:
、 和 为记忆单元的参数) |
|
时刻 输入数据的隐式编码:
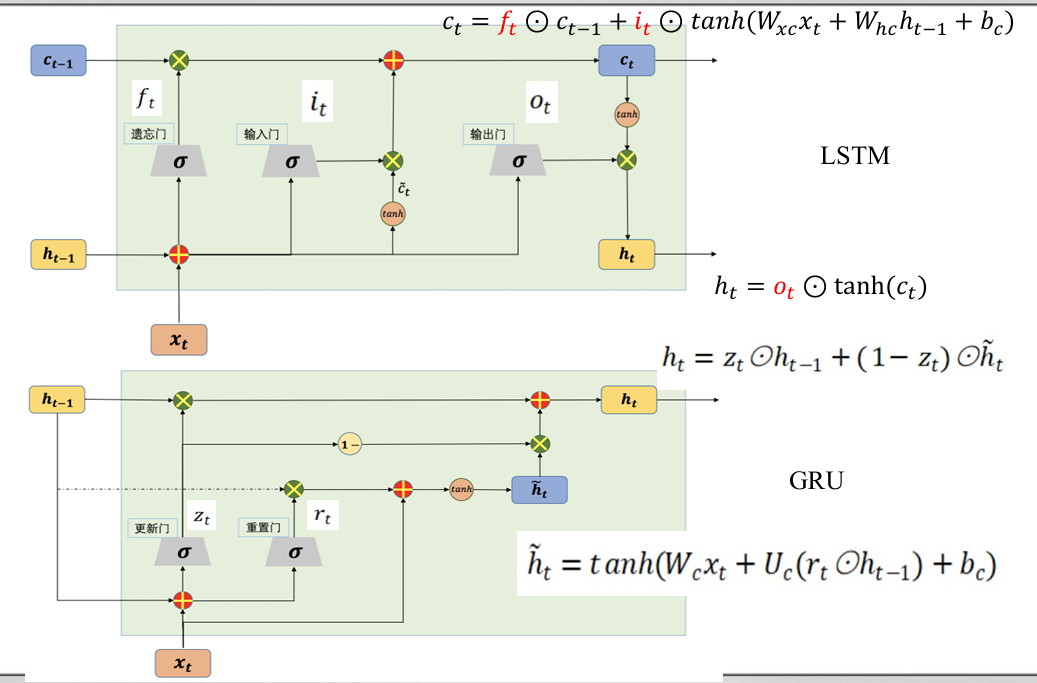
$$h_{t}=o_{t}\odot\tanh (c_{t})=o_{t}\odot\tanh (f_{t}\odot c_{t-1}+i_{t}\odot\tanh (W_{xc}x_{t}+W_{hc}h_{t-1}+b_{c}))$$
(输入门、遗忘门和输出门的信息 、、 一起参与得到 ) |
|
两个向量中对应元素按位相乘 (element-wise product)
如: |
一些细节:
- 三种门结构的输出 、 和 值域为
- 每个时刻 t 只有 作为本时刻的输出以用于分类等处理
- 实际上,在每个时刻 中只有内部记忆单元信息 和隐式编码 这两种信息起到了对序列信息进行传递的作用
- LSTM 如何克服梯度消失?
- LSTM 通过引入门结构,在从 t 到 t+1 过程中引入加法来进行信息更新,避免了梯度消失问题
GRU
门控循环单元(gated recurrent unit,GRU)神经网络
对 LSTM 作了一定的简化:不用记忆单元,仅使用隐藏状态来进行信息的传递
3.5 注意力机制
首先生成每个单词的内嵌向量 (包含了单词在句子中位置编码向量信息), 记为 , 如下计算每个单词 的查询向量 (query)、键向量 (key) 和值向量 (value):
- 查询向量: ;搜索单词
- 键向量: ;被搜索物品的描述信息
- 值向量: ;被搜索物品的语义内容
后面可以看到,对每个单词而言 、 和 三个映射矩阵都是一样的,也是自注意力模型需要训练的全部参数
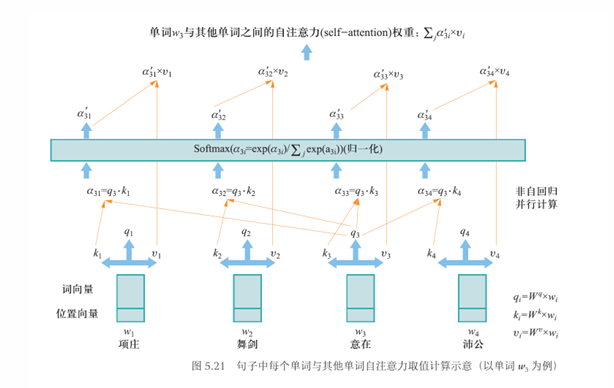
自注意力模型就是要挖掘单词 与其他单词在句子中因为上下文 (context) 关联而具有的自注意力取值大小。以图 5.21 中单词 与其他单词之间自注意力取值大小计算为例:
- 计算 所对应查询向量与其他单词健向量之间的点积,该点积可作为单词 与其他单词之间的关联度:
- 对 结果通过 softmax 函数进行归一化操作,得到
对于给定“项庄舞剑、意在沛公”句子, 记录了“意在”单词与其他单词所具有的重要程度 (即注意力)
- 乘以每个单词 所对应的值向量 , 即
- 对上一步结果进行 , 这个结果作为在当前句子语境下单词 “注意”到与其他单词的关联程度 (self-attention)
Multi-Head Attention: 构造不同的 Self-Attention 识别不同的特征
04 深度生成学习
生成模型需要学习目标数据的分布规律,以合成属于目标数据空间的新数据:
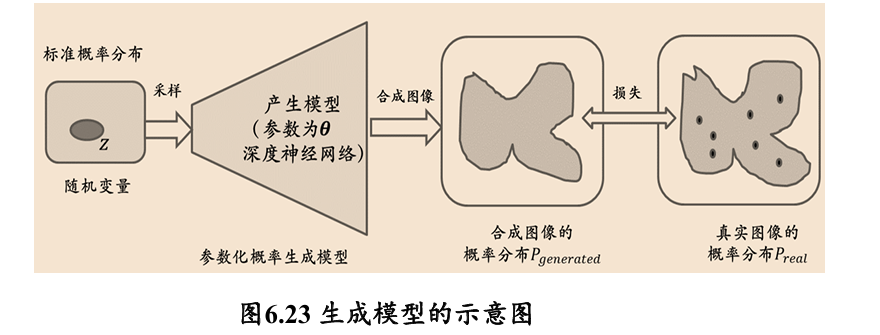
一些生成模型:
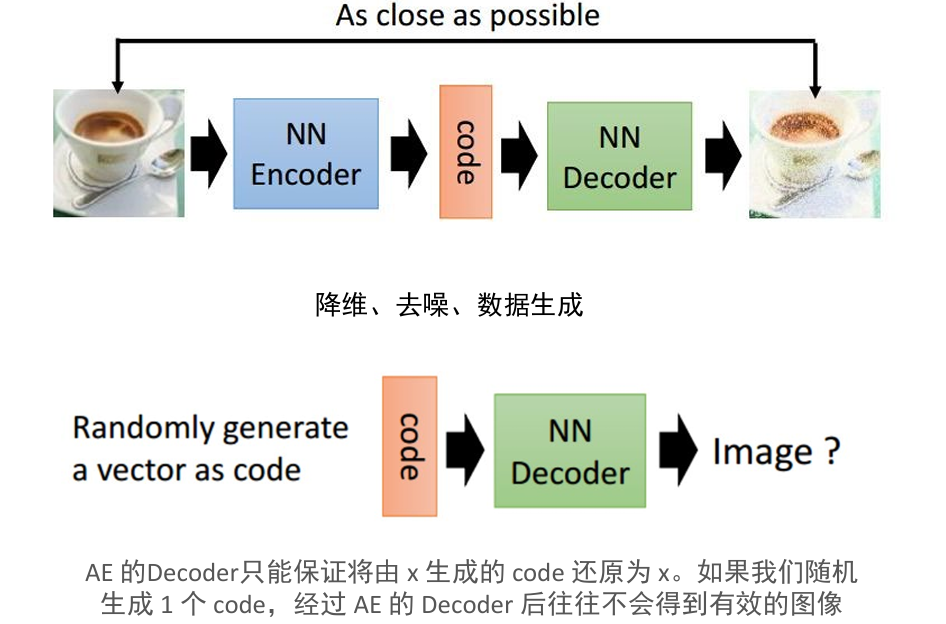
- 自编码器 Autoencoder AE
AE 的 Decoder 只能保证将由 x 生成的 code 还原为 x
如果我们随机生成 1 个 code,经过 AE 的 Decoder 后往往不会得到有效的图像
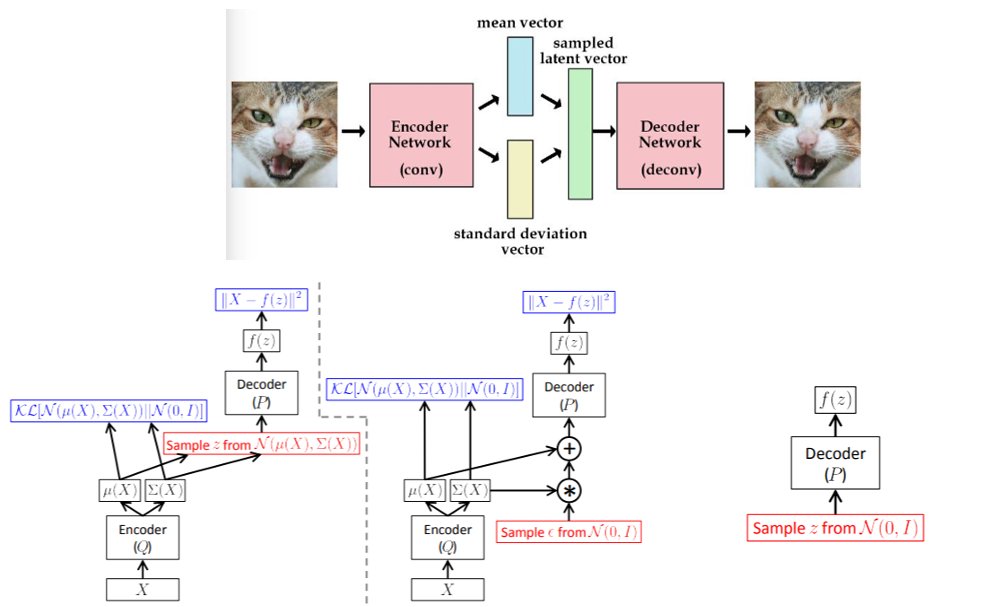
- 变分自编码器 Variational Autoencoder VAE
生成对抗网络 GAN
生成对抗网络由一个生成器(generator,简称 G)和一个判别器(discriminator,简称 D)组成
GAN 的核心是通过生成器和判别器两个神经网络之间的竞争对抗,不断提升彼此水平以使得生成器所生成数据(人为伪造数据)与真实数据相似,判别器无法区分真实数据和生成数据
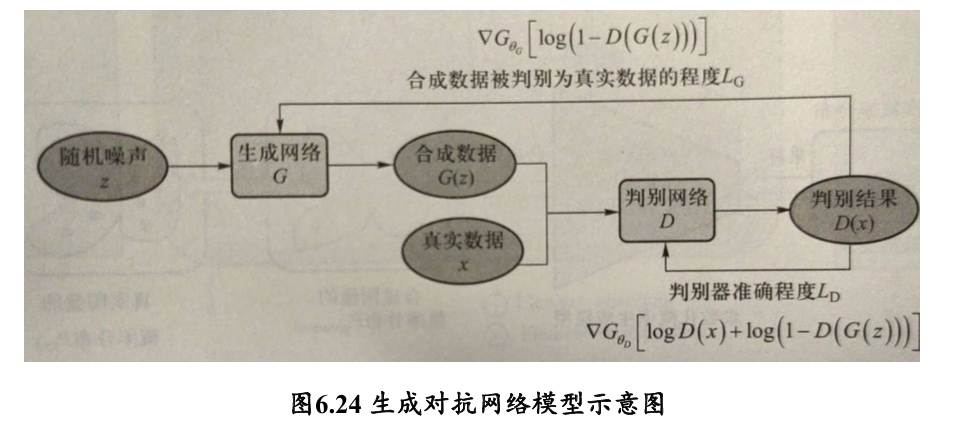
目标函数为:
- 输入:神经网络 D、G,噪声分布 pz (z),真实数据分布 pdata (x)
- 输出:神经网络参数θd、θg
- 算法步骤:
- 每轮训练循环执行:
- 训练 k 轮判别器:
- 从噪声分布 中采样 个样本
- 从真实数据分布 中采样 个样本
- 沿梯度上升方向更新判别器参数:
- 从噪声分布 中采样 个样本
- 沿梯度下降方向更新判别器参数:
GAN 具有收敛困难,且非常依赖于合适的交替训练轮次选择等不足,于是出现了 👇
Wasserstein GAN
- 模型输出不使用以概率值形式输出的 sigmoid 激活函数,而是直接根据输出值大小评价其效果
- 相应地,目标函数中也不需要再取对数:
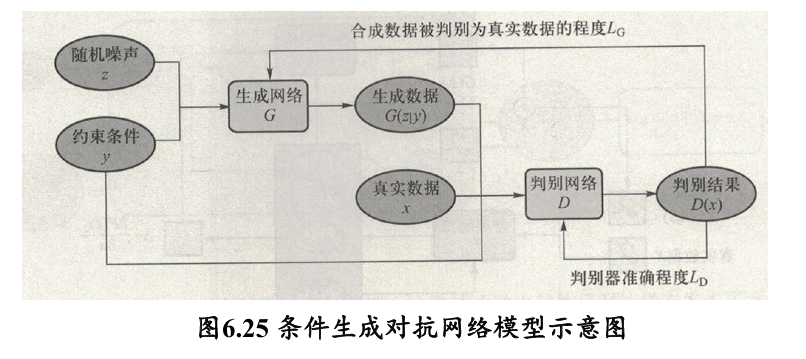
多了一个约束条件 y,输入到生成网络 G 和判别网络 D 中:
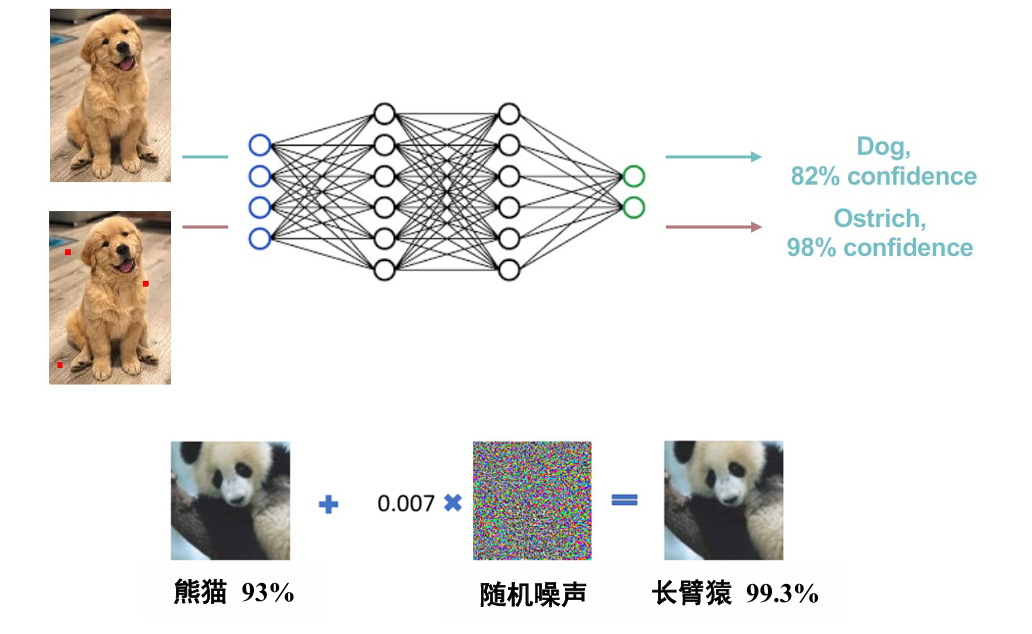
对抗样本攻击
加入随机噪声后,尽管人眼仍能明显地识别图像的主体,但神经网络会因此产生明显的判断错误:
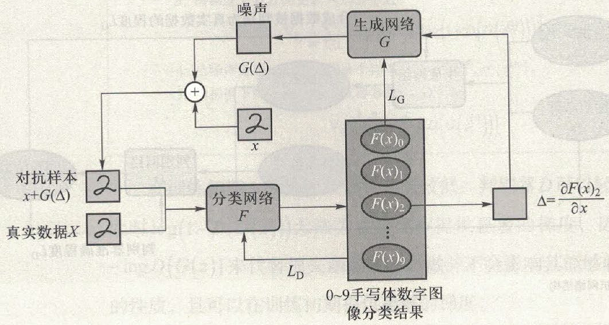
对抗生成训练器模型
- 让生成器扮演攻击者:高效地生成带有扰动的对抗样本,帮助分类网络学到"扰动"
- 让判别器扮演分类器
05 深度学习应用
“词袋”(Bag of Words)模型:一个单词按照词典序被表示为一个词典维数大小的向量(被称为 one hot vector),向量中该单词所对应位置按照其在文档中出现与否取值为 1 或 0。1 表示该单词在文档中出现、0 表示没有出现
分布式向量表达 (distributed vector representation) 👉 利用深度学习模型,可将每个单词表征为𝑁维实数值的分布式向量
Word2Vec
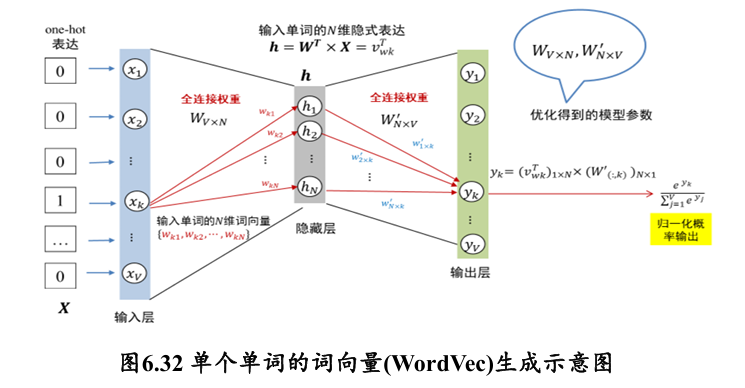
如何获得单个单词的词向量?
- 将该单词表示成 维 one-hot 向量
- 隐藏层神经元大小为 , 每个神经元记为
- 向量 中每个 与隐藏层神经元是全连接,连接权重矩阵为
- 这里 和 为模型参数
- 一旦训练得到了下图的神经网络,就可以将输入层中 与隐藏层连接权重为 (隐藏层) 作为第 个单词 维词向量 (word vector)
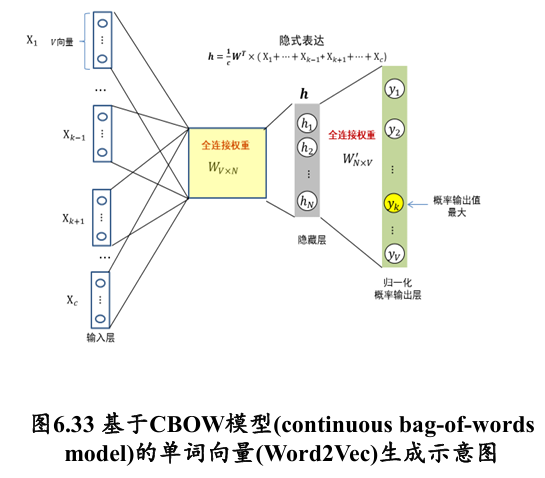
Continuous Bag-of-Words (CBoW):根据某个单词所处的上下文单词来预测该单词
可用 的前序 个单词和后续单词 个单词一起来预测
- 每个输入单词仍然是 维向量(可以是 one-hot 的表达)
- 隐式编码为每个输入单词所对应编码的均值
Skip-gram:利用某个单词来分别预测该单词的上下文单词
无论是 CBOW 还是 Skip-Gram 模式,随着单词个数数目增加,模型参数数目也迅速上升
👉 加快模型训练:层次化 Softmax(Hierarchical Softmax)与负采样(Negative Sampling)